
[Paper review] Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline
시작하며
시계열 데이터 분류 모델 개발을 위해 SOTA에서 time series classification을 키워드로 관련 논문을 찾아봤습니다. 관련 논문 중 가장 많이 구현된 논문으로 ‘Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline’을 찾게 되었고 본 논문을 토대로 시계열 분류 모델에 대한 인사이트를 얻고자 합니다.
이번 글에서는 논문 리뷰와 더불어 모델 초기 개발 방향을 설정하고자 합니다. 시계열 데이터 분류 모델의 여러 접근법에 대한 지식을 쌓고, 현재 보유한 데이터는 어떤 모델 또는 접근방식이 적합한지 판단하는 데 도움이 될 것입니다.
Introduce
논문은 시계열 데이터 분류 방법에 관해 설명합니다. 분류 방법으로 distance-based, feature-based, ensemble-based 들이 있는데 이들은 모두 데이터 처리 및 구현을 위해 많은 사전작업이 요구됨을 지적합니다. 최근에 이를 해결하기 위한 방법으로 deep neural network를 활용하고 있으며, 논문에서는 실험을 통해 심층 신경망으로 특별한 처리 없이 생성할 수 있는 시계열 데이터 분류 모델을 알아보고자 합니다.
Network architectures
모델 구조는 아래 이미지와 같습니다.
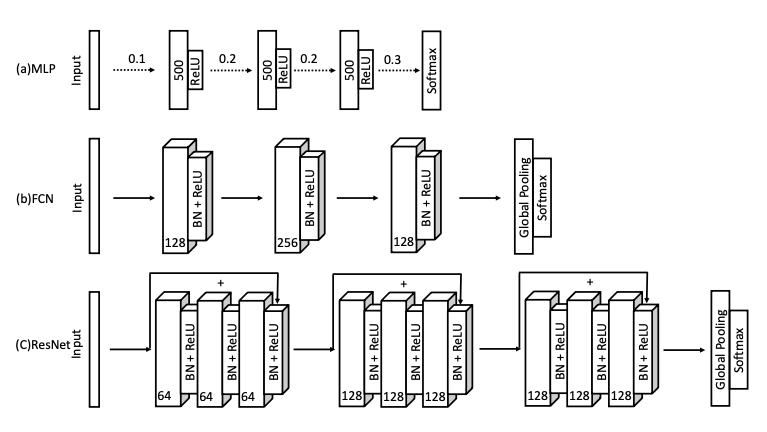
Multilayer perceptrons
기초적인 MLP 구조로 총 3개의 fully connected layer로 이뤄져 있습니다. 계층 사이에 Dropout으로 모델 과적합 방지 및 일반화 능력을 향상시키고, ReLU를 활성화 함수로 비선형 모델의 기울기 포화 상태를 예방합니다.
Fully convolutional networks
FCN은 총 3개의 convolution block으로 이뤄져 있습니다. block은 convolution layer로 batch normalization과 ReLU를 사용합니다. 각 block의 filter size는 128, 256, 128이며, 1-D kernel sieze는 8, 5, 3으로 마지막 layer로 global average pooling layer를 통과합니다.
Residual network
ResNet의 기본적인 구조는 앞선 FCN와 동일하며, 각 block의 filter size는 64, 128, 128을 따릅니다. 그리고 ResNet의 특징인 block마다 shortcut connection을 추가해 residual block을 형성하여 FCN와 차별점을 갖습니다.
Experiments and results
Experiment settings
UCR time sereis repository의 총 44개 시계열 데이터를 사용하여 결과를 비교합니다. 데이터 처리는 z-normalization만 적용하고, Optimizer로 MLP는 Adadelta(learning rate = 0.1), FCN과 ResNet은 Adam(learning rate= 0.001)을 사용합니다.
Evaluation
평가지표로 MPCE(Mean Per-Class Error)를 채택합니다. MPCE는 여러 데이터 셋에 대한 특정 모델의 분류 성능을 측정하기에 적합합니다. MPCE 수식은 아래와 같습니다.
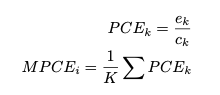
$c_k$: the number of class label
$e_k$: the corresponding error rate
Results and analysis
PCE score를 normalize한 결과는 아래 이미지와 같습니다.

처음 목표한 대로 FCN과 ResNet을 사용한 분류기가 좋은 성능을 보여주는 것을 확인할 수 있습니다. 그중에서 FCN은 다른 모델과 비교했을 때 가장 좋은 성능을 보여주고 있습니다. 그리고 다른 모델은 데이터 처리로 transformation, downsampling, window slicing 등이 필요하지만, deep neural network 모델은 이와 같은 처리도 필요 없습니다.
위 실험 결과로 deep neural network가 시계열 분류 모델에서 최적의 선택지임을 증명했습니다. 총 44개의 데이터에 대한 결과를 모두 확인해보니 FCN과 ResNet이 전체적으로 준수한 성능을 보이고 있었으며, 이는 기존의 복잡한 모델과 큰 차이가 없었습니다.
근데 여기서 의문점이 드는 부분은 MLP의 성능이 좋지 못한 부분이었습니다. 개인적인 생각으로 MLP는 convolution layer가 없어, 데이터를 시점(timestamp)이 아닌 구간(period)의 관점으로 데이터를 보지 못해 시계열 데이터의 특징을 도출하지 못했다고 봅니다. 즉, 단순히 convolution layer의 유무에 따라 이러한 차이가 생겼다고 판단했습니다.
Discussion
Overfitting and generalization
논문에서 UCR 시계열 데이터는 크기가 작고, 검증/테스트 데이터를 따로 사용하지 않아 과적합이 일어날 것으로 예상했다. 그러나 dropout과 batch normalization으로 모델 일반화를 도와 과적합을 방지했다고 보고 있으며, 이는 시계열 데이터도 다른 데이터와 동일하게 신경망 모델의 dropout과 batch normalization이 적용됨을 알 수 있었다.
Feature visualization and analysis
신경망 필터 가중치 시각화를 위해 GASF(Gramian Angular Summation Field)를 적용한 결과는 아래와 같습니다.
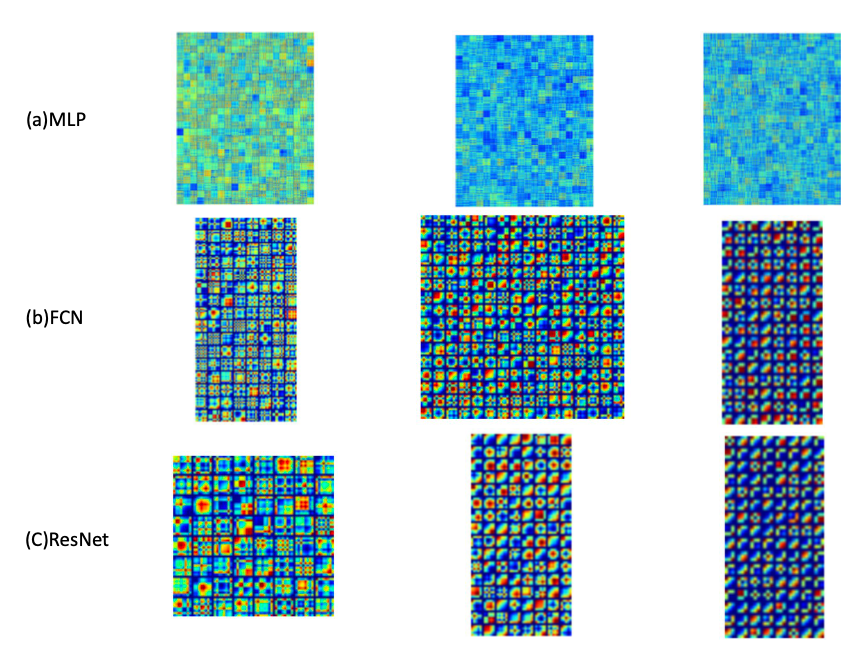
MLP는 첫 번째 layer가 상대적으로 높은 비중을 차지합니다. 즉, 첫 번째 layer에서 output을 거의 결정하고 다음 layer에서는 큰 변동이 일어나지 않습니다. 이는 MLP에서 비슷한 layer를 여러 개 사용해봤자, 인공 신경망 자체적으로 맨 처음 layer를 제외한 다음 layer는 크게 중요하게 생각하지 않는다고도 볼 수 있겠습니다.
FCN과 ResNet layer는 유사한 모습입니다. Convolution으로 특징을 추출하기 때문에 이전 MLP와는 다르게 비교적 뚜렷한 모습을 볼 수 있습니다. 그리고 layer가 깊어질수록 그 특징은 더 선명해져 분류기로써 좋은 성능을 보여주는 것입니다.
Deep and shallow
논문에서 결과적으로 ResNet이 FCN보다 떨어진 성능을 보였지만, 데이터 사이즈가 커지고 더 복잡해진다면 ResNet을 사용할 것을 권장하고 있습니다. ResNet이 strong interpretability와 generalization 사이에서 더 좋은 trade-off를 찾을 수 있기 때문입니다. 당연한 부분이라 생각합니다. 이미지에서도 ResNet이 더 좋은 성능을 보여주는 것과 마찬가지로 시계열 데이터도 동일할 것이고, 다만 데이터가 비교적 덜 복잡하기 때문에 단순한 FCN이 더 좋은 성능을 보여준 것이라 봅니다.
Classification semantics
분류 모델의 유사성을 확인을 위한 PCE score를 PCA로 축소 및 시각화한 결과는 아래 이미지와 같습니다.
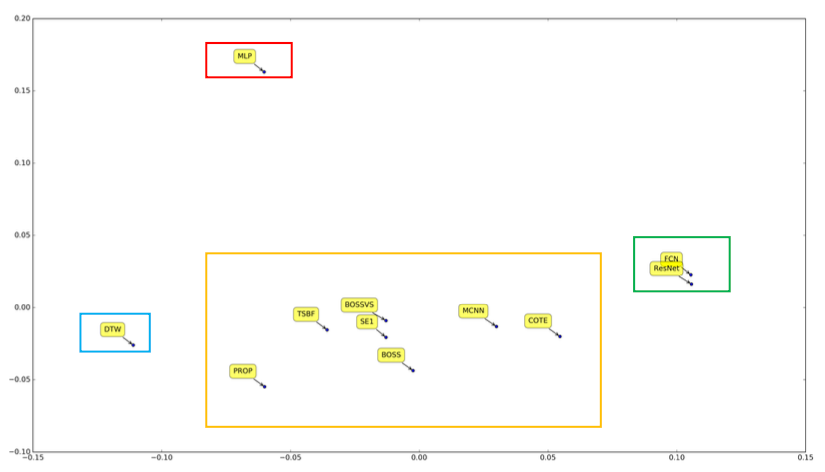
FCN과 ResNet은 매우 유사한 지점에 존재했으며, 여기서 특이한 점은 MLP만 다른 공간에 존재한다는 점입니다. 즉, MLP는 FCN, ResNet와 완전히 다른 분류기임을 의미합니다. MLP는 convolution layer를 사용하지 않기 때문에 이와 같은 결과가 나왔다고 생각합니다.
Conclusions
논문은 결과적으로 심층 신경망이 시계열 데이터 분류 모델의 strong baseline을 제공한다는 점을 말하고 있습니다. 데이터 처리 없이 전 과정을 신경망 모델로 구성해 다른 모델보다 우수한 성능을 보여줄 수 있음을 확인했습니다. 다른 방법들과 비교했을 때, 성능은 더 뛰어나고 추가적인 작업이 필요하지 않다는 점에서 논문에서 언급한 신경망 모델은 시계열 분석의 baseline으로써의 활용 가능성이 충분히 있다고 봅니다.
마치며
이번 글에서 시계열 데이터 관련 논문 리뷰를 진행했습니다. 논문을 단순히 읽는 데 그치지 않고, 리뷰 작성을 통해 더 깊이 생각해보고, 이해할 수 있어 유익했습니다.
결론적으로 시계열 분류에서 심층 신경망이 기존의 다른 접근방식보다 더 효과적임을 실험을 통해 증명하였고, Convolution layer로 데이터 특징을 추출해 이미지 데이터와 유사하게 분류에서 뛰어난 성능을 보여줌을 확인했습니다.
논문에서 CAM(Class activation map)에 대한 부분은 다음에 더 깊게 다뤄보면 좋을 것 같아 제외했습니다. 이미지 데이터와 유사하게 시계열 데이터에서도 어떤 부분이 output 생성에 중요한 역할을 했는지 검증하는 부분이 매우 흥미로웠으며, 다음에 Class activation map에 대해 더 알아보고 직접 구현까지 해보면 좋을 것 같습니다.
Reference
Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline, 20 Nov 2016
댓글남기기