
[Paper review] Learning Deep Features for Discriminative Localization
시작하며
딥러닝 모델은 심층 신경망을 활용한 모델로 이미지, 텍스트 등 비정형 데이터에서 뛰어난 성능을 보여주고 있습니다. 하지만 딥러닝 모델의 한계점으로 내부 구조가 어떻게 동작하는지 확인할 수 없다는 단점이 있습니다. 즉, 신경망의 어떤 부분이 중요하고, 데이터의 어떤 부분을 보고 모델이 판단하는지 모른다는 것입니다. 이와 같이 딥러닝 모델의 해석 불가능하다는 한계점을 해결하기 위해 XAI(eXplainable AI, 설명가능한 AI) 분야의 연구도 계속해서 진행되고 있습니다.
이번 글에서는 XAI와 관련된 CAM(class activation map)에 다루고자 합니다. 지난번 리뷰한 논문에서 딥러닝 모델을 CAM으로 설명한 부분이 매우 흥미로웠습니다. CAM에 대해서 더 알아보고 싶어져 관련 논문인 ‘Learning Deep Features for Discriminative Localization’을 리뷰하면서 자세히 파악해보도록 하겠습니다.
Introduce
논문에서는 최근 GoogLeNet과 같은 fully-convolutional neural network는 성능을 유지하면서 parameter를 최소화하기 위해 fully-connected layer 사용을 지향하는 방법을 제안하고 있다고 말합니다. Convolutional layer가 갖는 object detector의 기능이 fully-connected layer가 함께 사용된다면, 손실 될 수 있기 때문입니다.
실험을 통해 Convolutional layer가 갖는 이점을 활용한다면, 미세 조정을 통해 모델 네크워크가 마지막 레이어까지 localization ability가 유지될 수 있음을 증명하고자 합니다.
Localization이란 image classification에서 일종의 bounding box 개념으로 생각하시면 됩니다. 모델이 추정한 데이터의 위치 정보입니다.
Class Activation Mapping
CAM(Class Activation Map)은 이미지 분류에서 class 분류를 위해 dicriminative image regions를 형성합니다. 이미지가 해당 class가 갖는 차별적인 부분?(클래스 분류를 위한 부분)이 어디에 있는지를 class activation map을 통해 유추하는 것입니다.
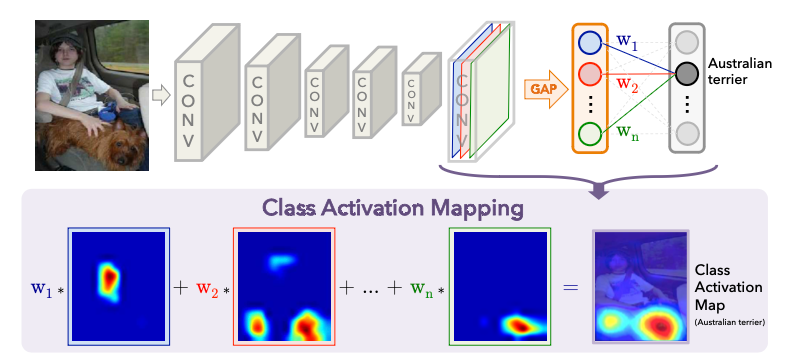
위 이미지와 같이 convolution layer를 지나 마지막 layer로 GAP(Golbal Average Pooling)를 활용 및 학습한다면, GAP의 weight를 통해 각 클래스에 해당하는 weight가 어느정도인지 파악할 수있습니다. 또한 CAM을 input image와 동일한 size로 upsampling한다면, 입력한 이미지의 어떤 영역이 해당 클래스의 localization인지 확인할 수 있습니다.(모든 클래스에 대해서 CAM을 활용하여 특정 이미지의 어떤 부분을 보고 특정 클래스로 유추했는지 시각적으로 확인할 수 있습니다.)
Deep Features for Generic Localization
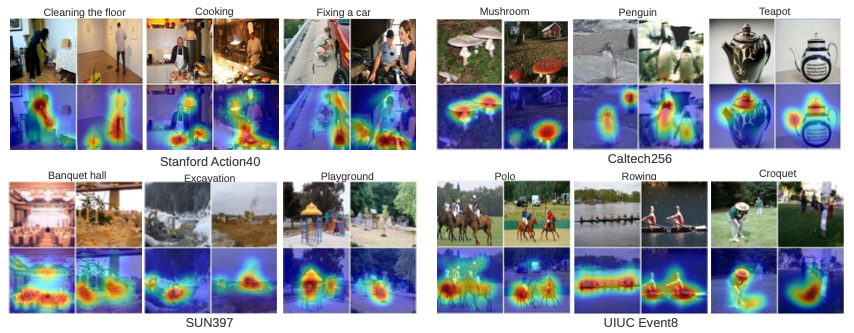
GoogLeNet과 CAM을 함께 사용하여 생성한 localization map에 대한 결과는 위 이미지를 통해 확인해볼 수 있습니다. 모든 데이터에 대해 discriminative region을 잘 표시했다고 보여집니다. 즉, GoogLeNet과 CAM을 사용한 접근방식은 일반적인 task에서 localizable deep feature를 생성하는데 효과적인 것입니다.
Fine-grained recognition에서 Fine-grained는 미세한, 세밀한을 의미합니다.
이번 챕터에서는 새에 대한 fine-grained recognition을 진행하며 어떻게 localization ability를 평가할 것인지에 대해 알아보고, 이를 성능 향상에 활용해보고자 합니다.
Fine-grained Recognition
실험에서 활용한 데이터(CUB-200- 2011)는 약 200종의 새에 대한 데이터로 localization ability를 적용 및 GoogLeNet-GAP의 성능을 비교하고자 합니다.
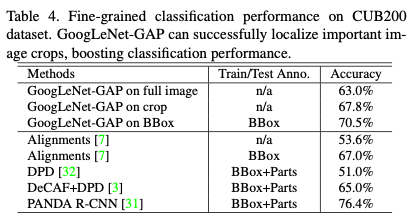
실험 결과로 위 표를 본다면, 전체 이미지를 사용한 정확도(63.0%)보다 GoogLeNet-GAP on BBOX 정확도(70.5%)가 더 높은 것을 볼 수 있습니다. 모델(ex. GoogLeNet-GAP)이 갖는 localization ability를 활용하여 이미지의 bounding box를 유추하고, 이 결과를 훈련에 사용한다면 더욱 성능좋은 모델을 만들 수 있는 것입니다.
그리고 GoogLeNet-GAP on crop 정확도(67.8%)와 비교했을 떄, 앞선 방식(localization ability 활용)이 더 좋은 성능을 보여주는 것을 볼 수 있습니다. Localization ability이 각 class가 갖는 미세한 차이(fine-grained)를 더 잘 식별할 수 있는 이미지를 일종의 bounding box를 생성해 주기 때문입니다. 아래 이미지는 GoogLeNet-GAP로 생성한 bounding box 결과입니다.

Conclusion
CAM은 CNN이 object localization을 형성하는 방법을 배울 수 있도록 합니다. 그리고 CAM을 사용하면 discriminative object를 점수로 표현 및 시각화할 수 있습니다. 또한, CAM을 사용한 localization은 다른 recognition 작업과 일반화(동일시)되는 것을 보여줍니다. 즉, CAM을 사용한 localization은 CNN task에서 basis of discrimination을 이해하는데 도움될 수 있는 deep feature를 생성합니다. 정리하자면, CAM을 사용해 유추한 class 고유의 deep feature for discriminative localization는 모든 CNN task에서 유의미한 결과를 가짐과 동시에 시각화로 확인할 수 있습니다.
마치며
논문에서 CAM에 대해 알아보았습니다. 성능 검증을 진행하고, CAM을 어떻게 활용할 수 있는지에 대한 부분도 다뤘습니다. GAP을 사용한 CAM에 대해 주로 실험한 결과를 다루고 있지만, CNN layer가 어떻게 데이터를 학습하는지도 CAM을 통해 확인해볼 수 있어 흥미로웠습니다.
본 논문을 통해 CNN이 데이터를 학습하는 방법과 모델 학습에서 어떤 부분을 중요시해야 하는지 알 수 있었습니다. CAM을 통해 본 데이터를 학습하는 방법은 이미지의 중요한 부분을 segment하고 segment한 부분을 통해 이미지를 판별하는 것입니다.(CNN도 결국 인간과 비슷한 로직으로 이미지를 인식하는 것 같았습니다.) 그리고 모델이 잘 학습하도록 이미지의 deep features for discriminative localization을 전달한다면, 모델 성능도 향상 될 것입니다.
이번 논문을 읽으면서 CAM에 대해 알아보고 더 나아가 CNN의 학습 과정에 대해 깊이 이해할 수 있어 유익했습니다. 다음에 논문에 나온 실험을 다른 데이터로 직접 구현하고 검증 해본다면 좋을 것 같습니다.
Reference
Learning Deep Features for Discriminative Localization, 14 Dec 2015
댓글남기기