
[Paper review] Time-Series Representation Learning via Temporal and Contextual Contrasting
시작하며
시계열 데이터 분류 관련 논문을 찾아보던 중, Time-Series Representation Learning via Temporal and Contextual Contrasting이라는 제목의 논문을 발견했습니다. 최근 Representation Learning에 관심이 생기기 시작했고, Abstract를 읽어보니 업무 관련하여 얻을 수 있는 부분도 많을 것 같아 본 논문을 리뷰하고자 합니다.
이번 글에서는 논문 리뷰 취지에 맞게 내용 설명을 기본으로 하고, 추가로 개인적인 이해와 느낀점을 정리할 것입니다. 논문에서 말하는 Representation Learning 방법에 대해 알아보고, 현업에 어떻게 적용할 수 있을지도 생각해 보겠습니다.
Introduction
시계열 데이터의 특성상 레이블링이 쉽지 않기 때문에 많은 양의 훈련용 데이터를 요구하는 딥러닝에서 시계열 데이터로 모델을 학습시키기는 어렵다고 말하고 있습니다. 이를 해결하기 위한 방법으로 레이블링 되지 않은 데이터를 이용한 Self-supervised learning(자기지도 학습) 중 하나인 Contrastive learning(대조 학습)에 대해 언급하며, 기존 대조학습은 시계열 데이터의 특징을 잘 반영하지 못해 적용하기엔 무리가 있다고 말합니다.
저자는 기존 대조 학습 문제를 개선한 Time-Series representation learning framework via Temporal and Contextual Contrasting(TS-TCC) 프레임워크를 개발했습니다. 프레임워크는 Data Augmentation(데이터 증강)으로 두 가지 다르지만, 연관성있는 데이터를 만들고, cross-view 예측을 통해 contrasting module이 데이터의 특징을 학습합니다. 즉, 모델은 과거 데이터의 특징으로 미래 증대된 데이터를 예측할 수 있습니다.
Introduction을 요약하자면, 아래와 같습니다.
- 시계열 데이터 자기지도 학습을 위한 대조 학습 프레임워크를 개발
- 대조 학습 프레임워크의 간단하지만, 효율적인 증강 기법을 고안
- 시계열 데이터의 representation을 학습하는 Temporal contrasting module 설계
- 세 개의 데이터를 사용하여 제안된 TS-TCC 프레임워크에 대한 실험을 수행.실험 결과, 학습된 representation이 지도 학습, 준지도 학습 및 전이 학습에서 효과적임을 보여줌
Related works
Self-supervised learning
자기지도 학습은 pretext task로부터 발전되었으며, pretext task는 heuristics에 의존하기 때문에 학습된 representation을 일반화하는 데 어려움이 있습니다. 반면에 Contrastive methods는 augmentation data로부터 invariant representation을 학습해 뛰어난 학습 효과를 보여주었습니다.
Pretext task는 unlabeled dataset을 input으로 사용하여 사용자가 정의한 문제(Pretext task)를 우선 학습시켜 데이터를 이해하기 위한 네트워크를 구축하는 것을 의미
Contrastive methods는 여러 방법이 있지만, temporal dependency와 같은 특성을 갖는 시계열 데이터에는 잘 동작하지 않습니다.
Self-supervised learning for time-series
시계열 데이터를 위한 representation learning의 인기는 점점 증가하고 있습니다. 접근방법으로 몇몇은 시계열 데이터를 위한 pretext task를 채택했습니다. 이와 다르게, 저자는 입력 데이터를 시계열 데이터의 specific augmentation을 구성하고, cross-view temporal과 contextual contrasting module로 시계열 데이터의 representation에 대한 학습 능력을 향상시키고자 합니다.
Methods
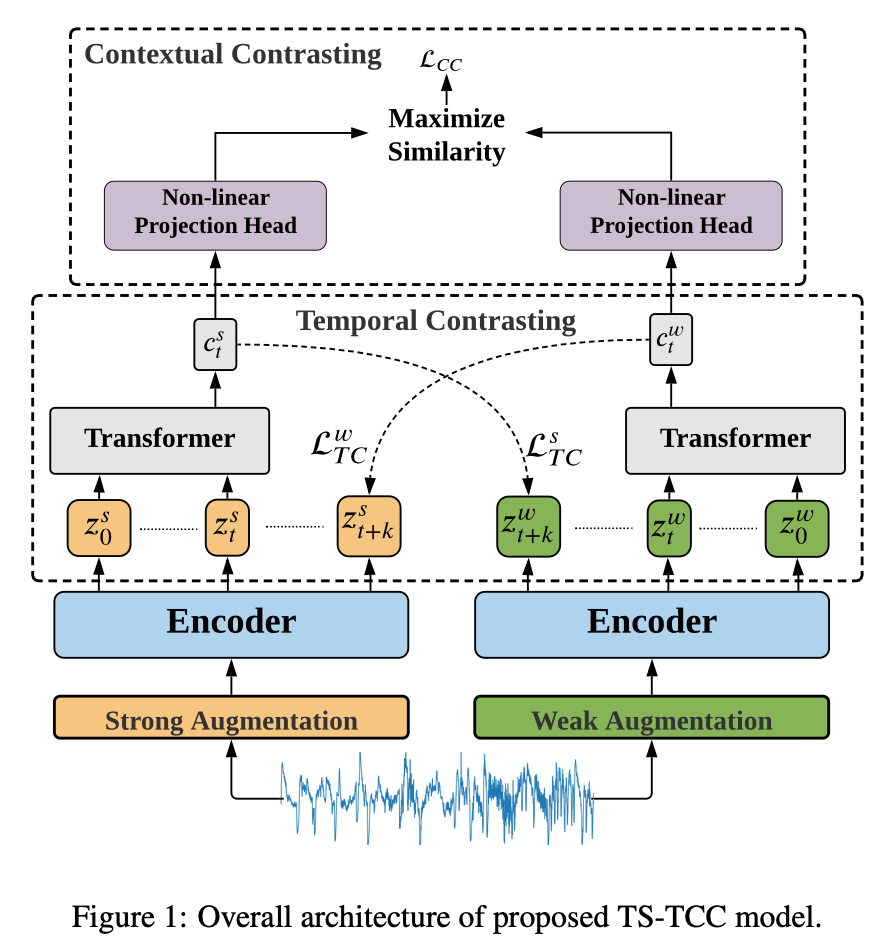
Time-series data augmentation
Data Augmentation은 contrastive learning의 성공에 핵심 부분입니다. Contrastive methods는 동일 샘플 간의 similarity를 최대화하고, 각기 다른 샘플 간의 similarity는 최소화하기 때문에 Data Augmentation이 중요합니다.
입력 데이터를 Strong augmentation(permutation-and-jitter), Weak augmentation(jitter-and-scale)으로 각각 augmentation하여 encoder로 들어갑니다. Encoder에서 데이터의 특징을 추출하여 이를 temporal contrasting 모듈로 전달합니다.
Temporal contrasting
Temporal Contrasting은 Autoregressive model로 latent space의 temporal feature를 추출하여 contrastive loss를 deploy합니다. Encoder와 Transfomer로 추출한 context vector로 contrasting하게 예측하는 것입니다. 예를 들어, Weak Augmentation을 거친 데이터가 Encoder와 Transformer를 통과한 뒤, context vector로 Strong Augmentation의 representation을 predict(예측)하는 것입니다.
Contrastive loss는 predicted representation이 batch 내에서 the true one of the same sample과 dot product(스칼라곱)을 minimize(최소화)하는 동시에 the other sample과의 dot product는 maximizing(최대화)합니다. Loss 계산식은 아래와 같습니다.
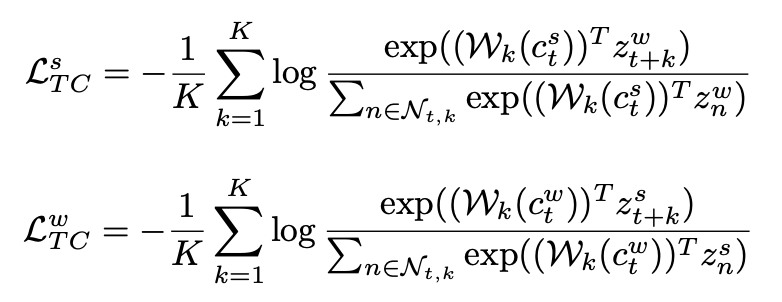
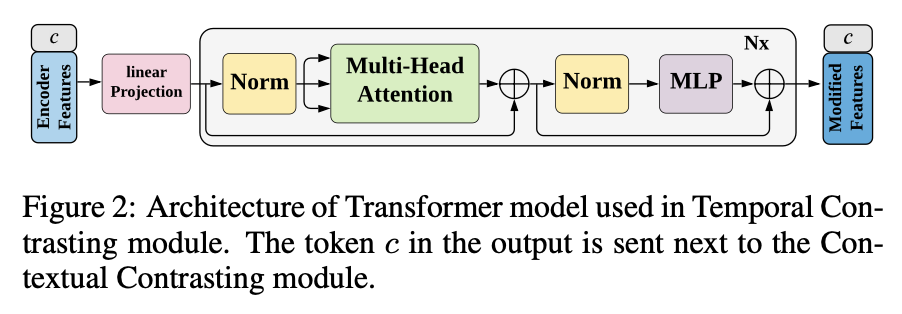
Autoregressive model로 효율과 속도가 좋은 Transformer를 사용했습니다. Transformer model의 구조는 아래와 같습니다. (Transformer에 대한 설명은 제외했습니다.)
다음으로 Transformer의 output(context vector)을 Contextual Contrasting module의 input으로 사용합니다.
Contextual contrasting
Contextual Contrasting module의 목적은 discriminative representation을 학습하는 것을 목표로 합니다. N개의 데이터를 갖는 batch가 주어졌을때, two augmented view(Strong Augmentation, Weak Augmentation)로부터 two context를 가질 수 있으며 총 2N개의 context vector를 얻을 수 있습니다. 여기서 동일한 sample로 얻은 2개의 context vector를 positive pair로 간주하고, 나머지 (2N-2)개의 context vector를 negative pair로 간주합니다. Contextual contrasting Loss는 앞서 지정한 positive pair의 similarity(유사도)는 maximize(최대화)하고 negative pair의 similarity는 minimize(최소화하)하는 방향으로 도출합니다.
Contrastive Learning. 데이터 x, y, z를 augmentation하여 x’, y’, z’을 생성하고 x와 x’의 similarity(유사도)를 maximize(최대화)하고 나머지 데이터 [x, y], [x, y’], [x, z], [x, z’]의 similarity를 minimize(최소화)하는 방향으로 학습하는 방법
Result
Comparison with baseline approaches
Baseline methods와 비교했을 때, TS-TCC의 성능은 총 3개의 데이터 중 2개에서 가장 좋은 성능을 보여줬습니다. 이로써 제안한 TS-TCC model의 representation learning capability의 뛰어난 효과를 추측할 수 있었습니다. 특히, contrastive method가 일반적으로 pretext-based method보다 더 나은 결과를 보여줬습니다. 게다가 CPC method가 SimCLR보다 더 나은 결과를 보여줌으로써, time-series 데이터에서 temporal feature가 general feature보다 더 중요한 feature임을 알 수 있었습니다.
Semi-supervised training
TS-TCC의 semi-supervised setting 효과에 대해 알아보기 위해 training data의 1%, 5%, 10%, 50%, 75%를 훈련에 사용했습니다. 아래 그림은 앞서 말한 조건에 대한 TS-TCC 결과입니다. TS-TCC FT(Fine-Tuning)는 few labeled samples로 pretrained 된 encoder를 사용했음을 의미합니다.
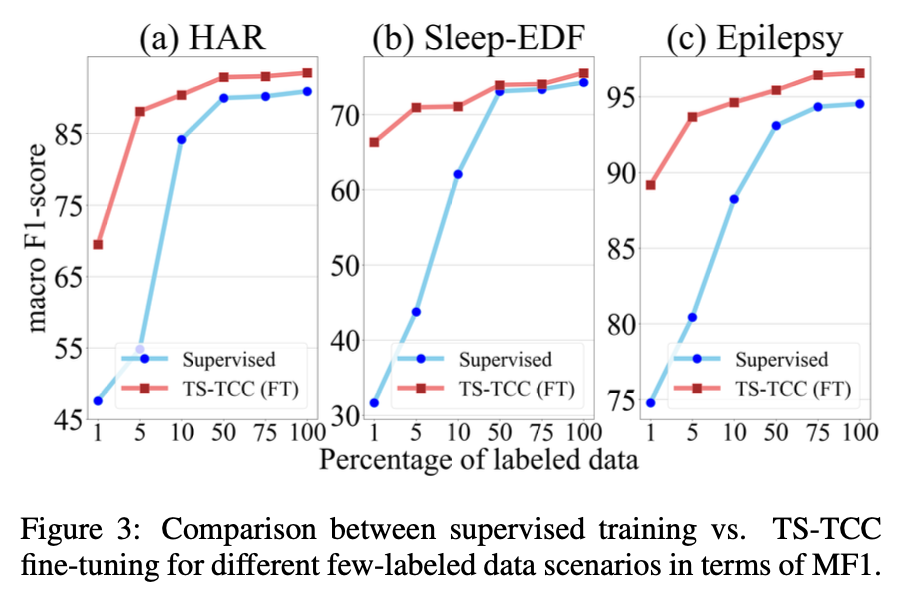
한정된 labeled data로 진행한 Supervised training perform은 좋지 않음을 확인할 수 있었습니다. 반면에, TS-TCC는 labeled data의 1%만 사용했을 때, supervised training보다 훨씬 더 나은 성능을 보여주고 있었습니다. 또한, TS-TCC는 labeled data의 10%만 사용하여 labeled data의 100%를 사용한 supervised training과 견줄만한 성능을 보여줍니다. 이는 semi-supervised learning에서 TS-TCC의 효과를 입증하고 있습니다.
Transfer learning experiment
학습된 특징의 transferability(전이성)을 검사하기 위해 transfer learning 환경을 구성했습니다. Source domain에서 훈련하고, 또 다른 target domain에서 훈련 및 테스트를 진행했습니다. 그리고 supervised training과 TS-TCC 두 개의 훈련 조건을 채택했습니다.
훈련 결과 TS-TCC는 supervised training과 비교하여 12개의 시나리오 중 8개에서 성능 개선을 보였습니다. 이를 통해 TS-TCC는 transferability of learned representation을 통해 supervised training보다 약 4%의 정확도를 향상시킬 수 있습니다.
Conclusions
본 논문에서 TS-TCC for unsupervised representation learning from time-series data라 불리는 프레임워크를 제안합니다. TS-TCC는 Strong and Weak augmentation으로 두 개의 각기 다른 view를 만들고, temporal contrasting module은 cross-view prediction을 적용하여 만들어진 robust temporal features를 학습합니다. 또한 contextual contrasting module은 discriminative features upon robust representation을 학습합니다.
본 논문의 실험에서 TS-TCC는 linear classifier에서 supervised training과 동등한 성능을 보여주고 있습니다. 게다가 TS-TCC는 few-labeled data와 transfer learning에서 높은 효율을 보여주고 있으며, 약 10%의 labeled data로 데이터 전부를 사용해 훈련한 supervised training에 근접한 성능을 달성했습니다.
마치며
논문에서 TS-TCC(Time-Series representation learning framework via Temporal and Contextual Contrasting)에 대해 알아보았습니다. 저자는 time-series data에 특화된 semi-supervised learning 방식을 고안했고, 실험으로 supervised learning과 성능 비교를 통해 성능을 입증했습니다. Time-series data의 특징을 고려해 augmentation, temporal contrasting 등을 설계한 부분이 가장 흥미로웠습니다. 개인적으로 아마 이 부분이 TS-TCC가 높은 성능을 보이는데 가장 큰 부분을 차지했을 것이라 생각합니다.
본 논문을 통해 semi-supervised learning의 기본적인 개념 및 원리에 대한 이해도를 높일 수 있었습니다. Representation learning, contrasting learning, semi-supervised learning 등 추상적으로 알고 있던 개념에 대해 깊게 살펴보며 이해할 수 있어 유익했습니다. 다음에 TS-TCC 프레임워크를 현업에 적용하기 위한 코드 리뷰를 진행해 보면 좋을 것 같습니다.
Reference
Time-Series Representation Learning via Temporal and Contextual Contrasting
https://github.com/emadeldeen24/TS-TCC/tree/main
댓글남기기