
Label smoothing for inductive bias
시작하며
한 달 전 NAVER에서 DEVIEW 2023을 주최했었습니다. 오프라인 컨퍼런스에 참석하기 위해 신청을 해보았으나, 엄청난 경쟁률에 신청은 처참히 실패하였고, 추후 공개되는 발표 자료와 영상을 통해 확인하기로 했습니다. AI가 메인인 만큼 AI 관련 세션이 가장 많았고, Python 최적화, MLOps를 위한 feature store 구축 등 흥미로운 세션이 많았습니다.
이번 글에서는 가장 흥미로웠던 세션인 ‘초등학생 AI모델 고등학교 보내기: Continual Learning으로 지속적으로 성장하는 AI 시스템’에서 언급한 label smoothing과 inductive bias에 대해 알아보고자 합니다. 쏘카에서 발표한 세션으로 classifier 학습에 활용한 기법인 label smoothing과 이를 통해 얻게 되는 inductive bias에 대해 순서대로 알아보겠습니다.
Label smoothing
Label smoothing이란?
Label smoothing이란 그대로 해석해보면, 레이블을 스무딩시킨다. 즉, 레이블에 스무딩(평활화)를 적용하여 모델 일반화 성능을 높이는 것입니다. One-hot-encoding 된(0과 1로 이뤄진) 레이블에 특정 값을 부여해 레이블이 0, 1이 아닌 0과 1 사이의 값으로 loss를 계산하고 학습하도록 합니다.
Label smoothing의 핵심은 hard target을 soft target으로 바꾸는 것입니다. N개의 class를 갖는 multi-classification task에서 n번째 레이블값은 아래와 같습니다.($ a $는 hyperparameter) \(y_{n}^{LS} = y_{n}(1 - \alpha) + \alpha/N\)
만약, 5개의 class를 갖는 classifier의 레이블을 만든다면, 3번째 class의 hard target은 $ [0, 0, 1, 0, 0] $과 같을 것입니다. 여기에 label smoothing($ \alpha=0.1 $)을 적용한다면, soft target은 $ [0.02, 0.02, 0.92, 0.02, 0.02] $과 같은 값을 가집니다.
Effect of label smoothing
머신러닝 모델은 실제값과 예측값의 차이인 loss를 최소화하는 방향으로 학습합니다. 그리고 생성한 레이블로 학습하기 때문에 입력한 레이블에 따라 모델도 다르게 학습합니다. 기존 multi-classification의 hard target은 오직 정답 class에만 값을 부여하기 때문에 출력값을 정답 class와 가깝게 하는 쪽으로만 학습하는 문제점이 있습니다. 이러한 경우 다른 class에 대한 가능성을 전혀 고려하지 않고 학습하기 때문입니다.
반대로 soft target은 출력값을 정답 class와 가깝게 만듦과 동시에 정답이 아닌 class도 고려하며 학습합니다. 정답이 아닌 class에도 일정 확률값을 부여하기 때문에 정답 class에만 exponential하게 학습하는 것을 방지할 수 있습니다. 또한, 만약 레이블이 잘못된 데이터에 대해서도 보수적으로 학습이 가능하다는 면에서 유리합니다.
아래 그림은 CIFAR100 데이터에 label smoothing을 적용한 시각화 자료입니다. 자료에서 보듯이 label smoothing으로 동일한 class끼리는 군집이 잘 형성된 모습을 볼 수 있습니다.
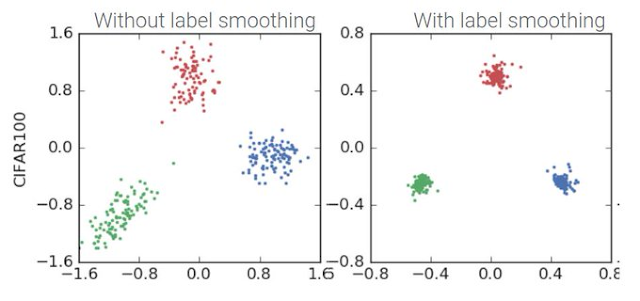
정리하자면, hard target을 label smoothing을 통해 soft target으로 변경하여 정답 class와 정답이 아닌 class를 동시에 학습하는 효과를 얻습니다.
Inductive bias
Inductive bias란?
머신러닝에서 bias는 모델 예측값과 실제값 차이의 평균으로, 얼만큼 두 값이 떨어져 있는지 나타냅니다. Bias가 높다면 예측값과 실제값의 차이가 크다는 것을 의미하고 모델이 과소적합 된 문제가 발생합니다. 즉, 모델은 예측값과 실제값의 차이를 최소화하는 것(bias 최소화)을 목표로 학습합니다.
일반적으로 모델은 task에 맞춰 데이터를 처리하고 학습하는 경우가 대부분입니다. 만약 학습 시 만나보지 못했던 데이터가 들어온다면, 모델이 어떻게 예측할지는 아무도 모르는 것입니다. 여기서, 모델이 학습하지 않았던 데이터 및 상황에 대해 정확한 예측을 하기 위한 추가적인 가정으로 inductive bias가 필요합니다.
Inductive bias는 보지 못한 데이터에 대해서 귀납적 추론이 가능하도록하여 모델 일반화 성능을 높이는 것입니다.
마치며
이번 글에서는 label smoothing과 inductive label에 대해 알아보았습니다. Label smoothing은 모델이 정답 class와 정답이 아닌 class를 동시에 학습하여 class 간의 구분을 더 명확히 할 수 있도록 만듭니다. 그리고 label smoothing을 통해 inductive bias를 구축하고 이는 모델의 일반화 성능을 향상시키고, 모델 성능 개선을 이룰 수 있었습니다.
Reference
https://ratsgo.github.io/insight-notes/docs/interpretable/smoothing
https://en.wikipedia.org/wiki/Inductive_bias
댓글남기기