
CAM(Class Activation Map)
시작하며
지난 포스팅에서 논문(Learning Deep Features for Discriminative Localization)리뷰를 작성했습니다. 리뷰를 작성하면서 실험을 통해 논문에 나온 CAM을 직접 구현해 보고 싶어졌습니다. 따라서, 이번 글에서는 이미지 데이터로 CAM을 직접 구현하는 실습 위주의 글을 작성해 보려 합니다.
진행 순서는 데이터를 수집 및 모델을 훈련시키고 테스트 데이터로 결과를 확인하는 기본적인 머신러닝 프로세스를 따릅니다. 테스트 데이터로 CAM 결과를 확인하고, 다음으로 유사한 데이터를 직접 수집 또는 촬영하여 결과를 비교합니다. 마지막으로 전혀 다른(관계없는) 데이터를 넣었을 때, 결과가 어떤지도 확인해 보며 실험을 마무리 하겠습니다.
Modeling
Data(Dogs vs Cats)
실험에 사용할 데이터는 강아지, 고양이 이미지 데이터입니다. Kaggle competition인 Dogs Vs Cats의 데이터로 강아지, 고양이 분류 모델 개발을 위한 데이터입니다.

위 이미지는 샘플데이터로 다양한 종류(품종)의 강아지, 고양이 데이터가 존재함을 확인할 수 있습니다. 데이터는 각 1,000개씩 총 2,000개로, 본 데이터를 활용해 모델을 학습시키고 결과를 확인해 보도록 하겠습니다.
Model
모델은 이미지 분류에서 좋은 성능을 보여주는 ResNet 알고리즘을 사용합니다. 문제(강아지, 고양이 분류)가 비교적 쉽고 단순하므로 ResNet 중에서 가장 얕은 ResNet18을 실험에 활용합니다. 모델 구조는 아래와 같습니다.
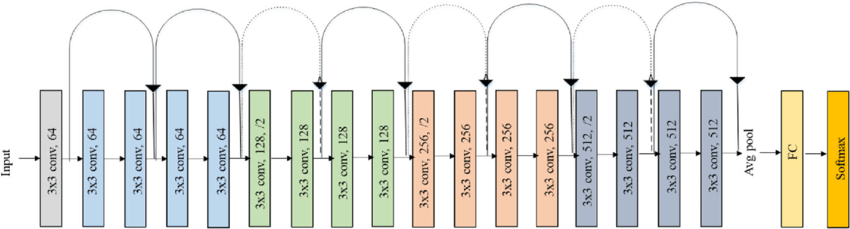
학습 시간 최소화를 위해 파이토치에 저장된 사전 학습된 모델을 파인튜닝합니다.
CAM(Class Activation Map)
모델 학습결과를 CAM으로 확인 및 비교해 보겠습니다. 만약, 훈련이 잘된 모델이라면 분류 성능이 좋을 뿐만 아니라 원본 이미지에 CAM이 적절하게 생성되어 있을 것입니다. 반대로 훈련이 잘되지 못한 모델이라면 분류 성능이 좋지 않을 뿐만 아니라 이미지에 형성된 CAM도 부적합할 것입니다.

위 이미지는 훈련 데이터에 대한 CAM 결과입니다. 모델은 대부분 이미지의 머리 쪽을 보고 강아지, 고양이를 분류하고 있는 것을 CAM으로 알 수 있었습니다. 여기서 흥미로웠던 점은 빨간 박스로 쳐진 잘못 예측한 결과입니다. 모델은 이미지의 머리 쪽 부분을 보고 고양이라고 잘못 예측했습니다. 즉, 이미지의 머리 쪽 부분이 제대로 나오지 않는다면, 모델이 잘못된 결과를 반환할 확률이 커질수 있는 것입니다. 이처럼 CAM으로 모델의 취약점을 파악할 수 있었습니다.
Model(Layer) 관점의 해석
모델의 CAM 형성 과정을 layer로 순차적으로 확인할 수 있습니다. ResNet18은 크게 4개의 층(layer)으로 이뤄져 있습니다. 각 layer의 output으로 생성한 CAM을 시각화하여 본다면, 모델이 이미지의 어떤 부분을 점차 집중하는지 알 수 있습니다.

위 이미지는 각 layer에 대한 CAM 결과를 시각화한 결과입니다. 앞서 말했듯이 모델은 3번째 layer부터 이미지의 머리 쪽 부분에 CAM을 형성하고, 4번째 layer에서 머리 쪽을 중심으로 CAM을 확장한 것을 볼 수 있습니다.
Data 관점의 해석
앞부분에선 모델 관점으로 CAM 결과를 살펴봤다면, 이번에는 데이터를 통해 CAM 결과를 살펴보겠습니다. 첫 번째는 직접 수집한 고양이 이미지로 결과를 확인해 보고, 두 번째로 강아지, 고양이가 아닌 이미지로 결과를 확인해 보겠습니다.

첫 번째 결과는 직접 수집한 고양이 이미지에 대한 결과입니다. 저희 집 고양이 사진을 모델에 입력시켜 보니 앞에서 살펴본 것과 유사한 결과가 나왔습니다. 모델은 이미지의 머리 쪽 부분을 중심으로 CAM을 형성하고 있었고, 머리 쪽 부분이 뚜렷하지 않은 아래 두번째 이미지는 강아지로 잘못 분류한 것을 볼 수 있었습니다.

두 번째 결과는 고양이상 연예인 이미지에 대한 결과입니다. 과연 모델이 고양이상 얼굴도 고양이로 인식하는지 궁금했습니다. 결과는 강아지로 잘못 인식했지만, 모델이 생성한 CAM 결과를 보면 얼굴 쪽 부분에 CAM을 올바르게 형성한 것을 확인할 수 있었습니다.
데이터 관점에서 결과를 파악해보니, 모델이 생성한 CAM으로 모델의 취약점이 무엇인지와 반대로 어떤 부분을 잘 잡아내는지를 알 수 있었습니다.
마치며
이번 글에서 논문(Learning Deep Features for Discriminative Localization)에 나온 CAM을 직접 코드로 구현하고, 다양한 데이터로 결과를 직접 살펴보았습니다. 모델 학습 과정을 각 layer에 대한 CAM 결과로 확인할 수 있었으며, 모델이 데이터마다 어떤 부분에 중점을 두고 분류했는지도 알 수 있었습니다.
Reference
https://www.kaggle.com/c/dogs-vs-cats
댓글남기기