
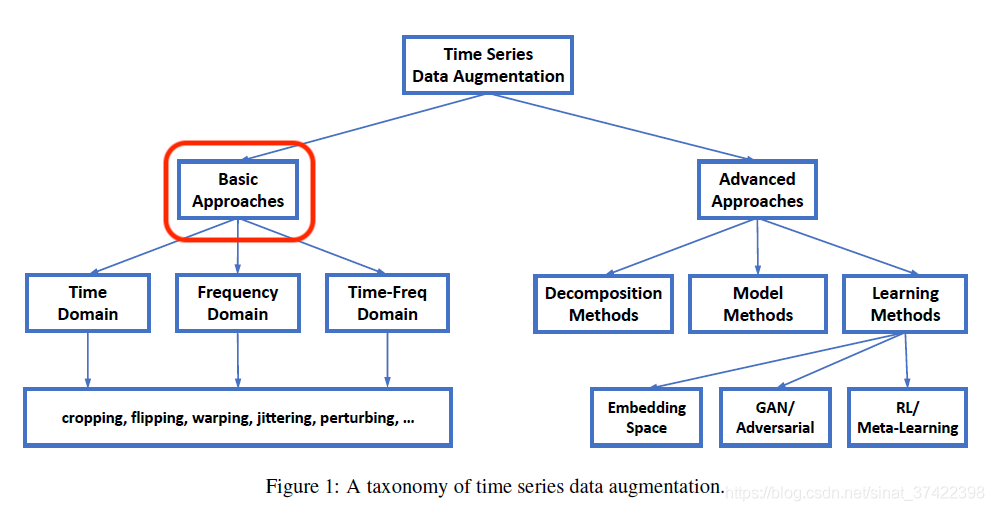
Augmentation of Time series data
시작하며
시계열 데이터는 일정한 시간 간격으로 발생하는 시간에 따라 정렬된 데이터를 의미하며, 오늘날 제조, 금융, 의료 등 다양한 분야에서 발생하고 있습니다. 그리고 현업에서 머신러닝(회귀, 분류)을 위한 시계열 데이터는 다른 분야(이미지, 텍스트 등)와 같은 목적으로 활용됩니다.
다른 분야는 웹상에 공유된 데이터도 많고 바로 서비스 적용할 수 있는 수준의 모델도 많아 개발에 어려움이 없지만, 시계열 분야는 데이터도 별로 없을뿐더러 분류, 예측 등 목적에 특화된 모델 개발도 많이 진행되지 못해 개발에 어려움이 많습니다.
이러한 문제 해결 방법의 하나인 데이터 부족 문제를 해결하는 데이터 증강(Data augmentation)에 대해 알아보고자 합니다.
데이터 증강(Data augmentation)
데이터 증강이란?
데이터 증강이란 데이터양을 늘리기 위한 기법으로, 보유한 데이터에 여러 변환을 적용하여 데이터 수를 증가시킵니다. Computer Vision 분야에서 필수로 사용되며, 아래 이미지와 같이 원본 이미지를 다양한 방식으로 변환해 원본 데이터에서 학습하지 못했던 부분을 모델이 학습할 수 있도록 합니다.
 ➡️
➡️ 
데이터 증강으로 원본 이미지의 고유한 특성(고양이)은 유지한 새로운 이미지(고양이)를 생성하였고, 그 결과 한정적인 훈련 데이터의 양을 증가시켜 모델 성능을 높이고 과적합 문제를 해결할 수 있습니다.
시계열 데이터 증강
데이터 증강은 시계열 데이터에도 적용할 수 있습니다. 시계열 데이터의 경우 데이터 수집이 어렵고 비용이 많이 들기 때문에 데이터 증강 기술이 유용하게 활용됩니다.
일반적으로 시간이 지남에 따라 변화하는 시간 축을 가지고 있으므로, 증강 기법은 시간 축을 활용하여 데이터를 변형합니다. 시간 축을 이동하거나(Shift), 회전시키거나(Rotation), 노이즈를 추가하거나(Noise), 일부 구간을 제거하거나(Crop), 데이터를 뒤집는(Reverse) 등의 다양한 기법을 적용할 수 있습니다.
이를 통해 새로운 시계열 데이터를 생성하고 모델 학습에 이용해 데이터의 다양성을 확보하고 성능을 향상시킬 수 있습니다.
데이터 증강 기법
시계열 데이터 증강 기법은 크게 원본 데이터를 단순 변형하는 방법과 생성 모델(Generative model) 개발을 통한 새로운 데이터를 생성하는 방법이 있습니다. 본 포스팅에선 기존 데이터를 단순 변형하는 방법에 대해 알아보고, 증강 기법을 코드로 구현 및 시각화 자료로 결과를 확인하고자 합니다.
1. Cropping
Cropping은 원본 데이터의 일부 구간을 잘라내는 기법입니다. 데이터 일부분을 제거하여 정보 손실이 있지만, 제거한 부분이 원본 데이터에서 불필요한 부분이라면 학습에 최적화된 데이터를 생성 및 활용하는 것으로 볼 수 있습니다. 이처럼 cropping을 통해 원본 데이터의 특징을 도출하고 불필요한 데이터를 제거한 새로운 데이터를 생성합니다.
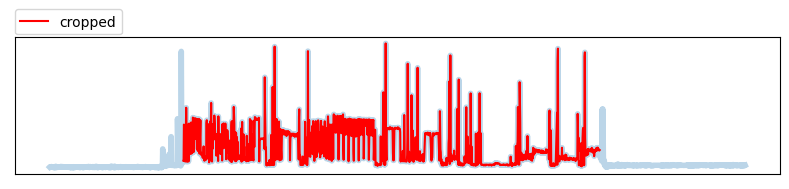
Time cropping
전체 구간을 cropping 하는 방법으로 데이터의 시작, 끝부분을 특정 길이만큼 제거합니다. 전체 길이의 cropping 할 percentage를 입력하여 시작, 끝부분에 각각 적용합니다. 그 결과 아래와 같이 불필요한 데이터를 제거할 수 있습니다.
def time_crop(series, pct=0.1):
"""
inputs
series
a pandas Series, must have DatetimeIndex
pct
a cropping percentage, within interval [0.0, 0.5] (default 0.1)
output
series
a pandas Series with DatetimeIndex
"""
sr_len = len(series)
start, end = (int(sr_len*p) for p in np.random.uniform(0, pct, size=2))
return series[start:-end]
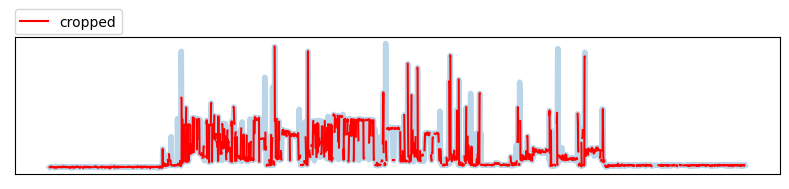
Window cropping
데이터를 일정한 간격으로 cropping 하는 방법으로 데이터 일부분을 제거합니다. 시작, 끝부분만을 제거하는 Time cropping과 다르게 전체적으로 균등하게 데이터를 제거합니다.
def window_crop(series, freq=100, pct=0.1):
"""
inputs
series
a pandas Series, must have DatetimeIndex
freq
a frequency integer to be used as cropping difference (default 100)
pct
a cropping percentage, within interval [0.0, 0.5] (default 0.1)
output
series
a pandas Series with DatetimeIndex
"""
sr_len = len(series)
idx = np.arange(0, sr_len)
crop_size = int(freq * np.random.uniform(0, pct, size=1))
in_freq = np.array([np.arange((freq * i), (freq * (i+1)) - crop_size) for i,j in enumerate(idx[freq::freq])]).ravel()
out_freq = idx[-(sr_len % freq):]
pos = np.concatenate((in_freq, out_freq))
return series[pos]
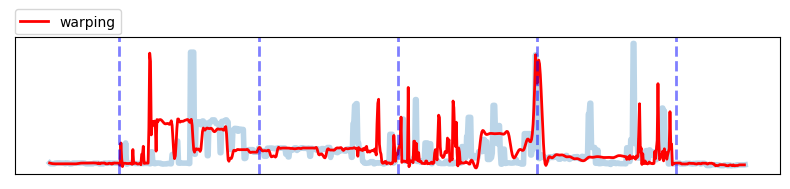
2. Warping
Warping은 원본 데이터의 일부 구간을 압축 또는 확장시키는 기법입니다. 시계열 데이터의 시간 축을 일정한 시간만큼 이동시켜 새로운 데이터를 생성하는 방법으로 모델이 데이터의 시간 축 변동에 대해 잘 학습할 수 있도록 도와줍니다. 예를 들어, 특정 이벤트가 발생한 시점에서 데이터의 패턴이 변화할 수 있습니다. 이러한 패턴을 모델이 잘 학습하기 위해 시간 축을 이동시켜 새로운 변화된 패턴을 생성합니다.
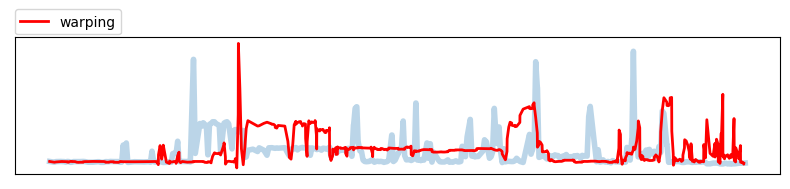
Time warping
전체 구간을 warping 하는 방법으로 전체 데이터를 서로 다른 n개의 데이터로 분할하고, 분할된 데이터를 압축 또는 확장시켜 새로운 데이터를 생성합니다.
from scipy.interpolate import CubicSpline
def time_warping(series, n_warp=5, pad=10):
"""
inputs
series
a pandas Series, must have DatetimeIndex
n_warp
a number of warping list (default 5)
pad
a padding length (default 10)
output
series
a pandas Series with DatetimeIndex
"""
def __fit_spline(y, size):
spl = CubicSpline(np.linspace(0.00, 1.00, len(y)), y)
return spl(np.linspace(0.00, 1.00, size))
sr_len = len(series)
idx = np.arange(pad, sr_len-pad)
_ts_points, _val_points = np.zeros(n_warp), np.zeros(n_warp)
while len(np.where(np.abs(_ts_points - _val_points)<pad)[0]):
_ts_points, _val_points = (np.sort((np.random.choice(idx, n_warp-1))) for _ in range(2))
ts_points, val_points = np.hstack((np.array([0]), _ts_points, np.array([sr_len-1]))), np.hstack((np.array([0]), _val_points, np.array([sr_len-1])))
ts, val = series.index.values, series.values
lst = [[ts[ts_points[i]:ts_points[i+1]], val[val_points[i]:val_points[i+1]]] for i,p in enumerate(ts_points[:-1])]
return pd.concat([pd.Series(__fit_spline(_ls[1], size=len(_ls[0])), index=_ls[0]) for _ls in lst])
Window warping
데이터를 일정한 간격(window)으로 waping 하는 방법입니다. Time warping과는 다르게 전체 데이터를 균등하게 분할 및 warping 하여 상대적으로 변환 효과를 줄여 기존 특성을 최대한 보존하면서 warping을 진행합니다.
def window_warping(series, window=0.2):
"""
inputs
series
a pandas Series, must have DatetimeIndex
window
a percentage for window size, within interval [0.0, 0.5] (default 0.2)
output
series
a pandas Series with DatetimeIndex
"""
sr_len = len(series)
idx = np.arange(sr_len)
freq = int(sr_len * window)
pad = np.array([np.nan] * ((freq - (sr_len % freq))//2))
idx_lst = np.concatenate((pad, idx, pad)).reshape(-1, freq)
return pd.concat([time_warping(series.iloc[_ls[~np.isnan(_ls)]], n_warp=2, pad=10) for _ls in idx_lst])
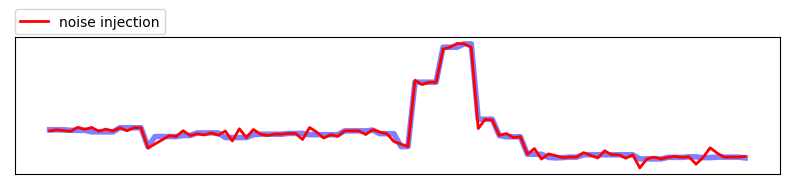
3. Noise injection
Noise injection은 랜덤한 노이즈를 시계열 데이터에 추가하여 데이터를 변형시키는 기법입니다. 노이즈 주입은 모델이 더 다양한 패턴을 학습하도록 하며, 모델을 더욱 강건하게 만드는 효과가 있지만, 너무 많은 노이즈가 추가될 경우 모델의 성능을 저하시킬 수도 있습니다. 따라서 적절한 노이즈 크기와 종류를 선택하는 것이 중요합니다.
White noise injection
White noise는 백색잡음으로 불리는 대부분 데이터에서 쉽게 발견되는 노이즈입니다. white noise injection은 원본 데이터 특성은 유지하고 자연적인 노이즈(백색잡음)만 랜덤하게 추가하는 방법입니다.
def white_noise_injection(series, pct=0.1):
"""
inputs
series
a pandas Series, must have DatetimeIndex
pct
a percentage of noise injection, within interval [0.0, 1.0] (default 0.1)
output
series
a pandas Series with DatetimeIndex
"""
temp = series.copy()
def __filter_out_1sigma(arr):
mu, sigma = np.mean(arr), np.std(arr)
return arr[((mu - sigma) <= arr) & (arr <= (mu + sigma))]
sr_len = len(temp)
idx = np.arange(sr_len)
_dif = np.diff(temp.values)
dif = __filter_out_1sigma(_dif)
_mean, _std = np.mean(dif), np.std(dif)
pos = np.random.choice(idx, int(sr_len * pct))
noise = np.random.normal(_mean, _std, size=len(temp))[pos]
temp.iloc[pos] += noise
return temp
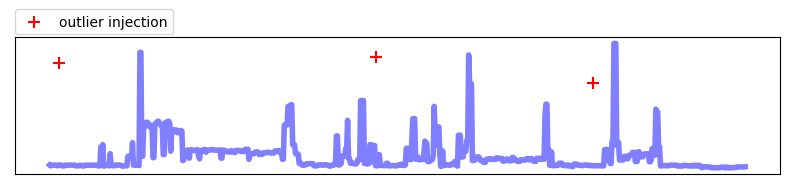
Outlier injection
Outlier injection은 원본 데이터에 임의로 이상치(outlier)를 추가하는 방법입니다. 이상 탐지를 위한 데이터를 임의로 생성 및 모델 학습에 활용할 수 있습니다.
def outlier_injection(series, pct=0.005):
"""
inputs
series
a pandas Series, must have DatetimeIndex
pct
a percentage of noise injection, within interval [0.0, 1.0] (default 0.005)
output
series
a pandas Series with DatetimeIndex
"""
temp = series.copy()
def __filter_outlier(arr):
outlier = np.quantile(arr, 0.995)
return arr[(arr>=outlier)]
sr_len = len(temp)
idx = np.arange(sr_len)
_dif = np.diff(temp.values)
dif = __filter_outlier(_dif)
_mean, _std = np.mean(dif), np.std(dif)
pos = np.random.choice(idx, int(sr_len * pct))
noise = np.random.normal(_mean, _std, size=len(temp))[pos]
temp.iloc[pos] += noise
return temp
마치며
머신러닝에서 데이터 증강은 기존 데이터를 변형시켜 새로운 데이터를 생성하는 기술입니다. 이를 통해 모델은 다양한 패턴을 학습하고 일반화 능력을 향상시킬 수 있습니다. 또한 데이터 증강은 일반적으로 데이터 크기를 증가시키는 데 사용되며, 모델 과적합을 방지하고 데이터 불균형 문제를 해결하는 데도 유용합니다.
이번 글에서 시계열 데이터 증강기법으로 단순 변형 방법 3가지(Cropping, Warping, Injection)를 알아봤습니다. 증강기법을 직접 코드로 구현해보고 시각화 결과를 확인하며 쉽게 이해할 수 있었습니다. 아직 실제 모델에 증강한 데이터를 활용해 본 적이 없어 효과를 직접 검증해보진 못했지만, 샘플 데이터로 증강을 진행해보면서 대부분 원본 데이터의 특성은 보존하고 있는 것을 확인했습니다. 이를 통해 시계열 데이터 증강이 모델 고도화에 충분히 유의미한 기술임을 확신할 수 있었습니다.
다음 글에서는 한 단계 나아가 생성 모델을 활용한 데이터 증강, 데이터 증강의 한계 및 과제는 어떤 것들이 있는지 알아보고 작성해보겠습니다.
댓글남기기